




レトリバが発表した日本語検索向けテキスト埋め込みモデル「AMBER」
株式会社レトリバが新たに発表したテキスト埋め込みモデル「AMBER」
AI技術を駆使して、企業のニーズに応える株式会社レトリバ(東京都豊島区)。2023年、同社は日本語検索に特化したテキスト埋め込みモデル「RetrievaEmbedding - 01 AMBER (Adaptive Multitask Bilingual Embedding Representation)」の公開を発表しました。このモデルは、日本語の検索精度を向上させることを目的としています。
日本語検索の課題を克服するために
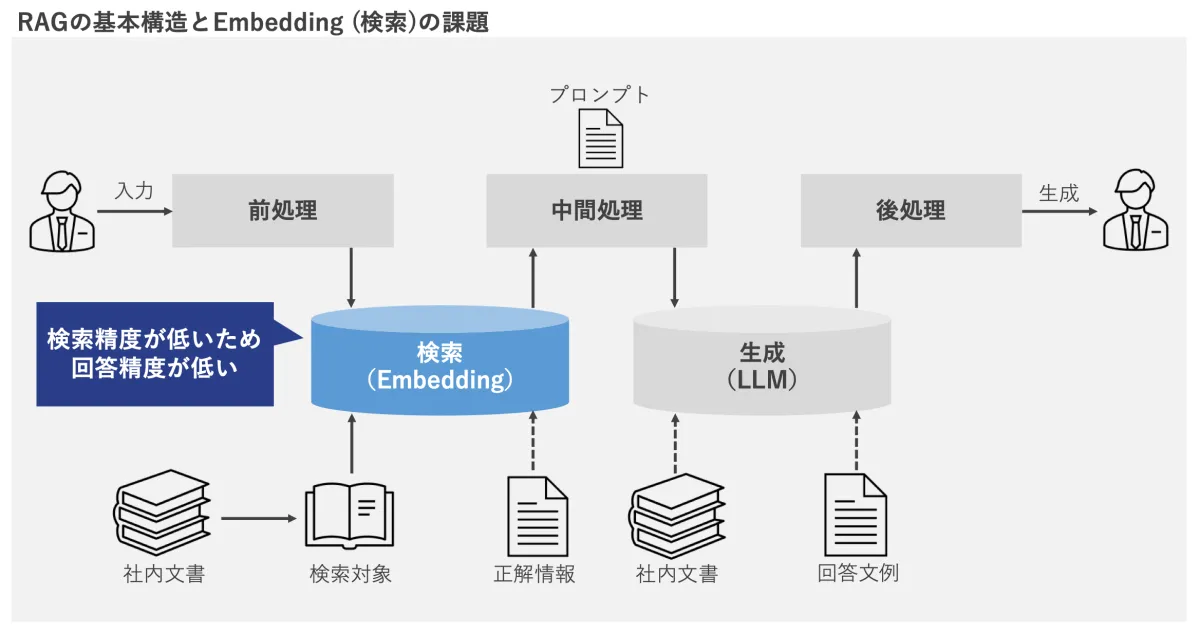
現在、日本企業における生成AIの活用は欧米と比較して発展途上にあります。特に、情報精度の向上を期待されるRAG(Retrieval-Augmented Generation)技術は多くの企業で求められていますが、実際の導入は進んでいないのが現状です。
その主な理由の一つとして、RAGに必要なEmbedding技術が日本語モデルにおいて不十分であることが挙げられます。多くの企業は、精度が低いEmbeddingモデルを使用し、結果として生成される情報の精度が損なわれるという問題を抱えています。これによって、日本企業のAI技術活用が制約されています。
株式会社レトリバは、こうした課題を克服すべく、長年の自然言語処理技術の研究・開発を基に、AMBERという高精度の日本語Embeddingモデルを作り上げました。
AMBERがもたらす新たな可能性
AMBERは、特に日本企業の社内検索において、高い検索精度を実現したモデルです。以下にその特徴を詳しく説明します。
1. 高精度の日本語検索
AMBERは、コンパクトなモデルサイズ(パラメータ500M以下)でありながら、日本語の検索精度を測るテストにおいて、既存の多言語モデルに対して最も高いスコアを記録しました。この結果は、本モデルが実務での利用において非常に効果的であることを示しています。
2. 英語ドキュメントとの併用
日本の業務環境では、日本語と英語が混在するドキュメントが多く存在します。このため、情報検索の際に言語の壁が生じることが少なくありません。AMBERは、日本語検索において高い精度を維持しながら、英語情報も適切に処理することが可能です。これにより、様々な業務に適合したEmbeddingモデルとなっています。
商用利用のサポート
このAMBERモデルは、以下のHugging Face Hubで利用可能です。
商用利用も可能なライセンスで提供されており、多くの企業がスムーズに導入できるよう配慮されています。
今後の展開と実用化
将来的には、日本企業におけるRAGの重要性が一層高まることが予想されます。そのため、AMBERのファインチューニングを通じて、業界特有の用語に特化した検索モデルの開発を進める計画です。この取り組みを実現するために、企業とのコラボレーションを強化していきます。
会社概要
株式会社レトリバは「AI技術で、人を支援する」を使命としており、自然言語処理や機械学習を駆使して、企業が持つデータの価値を最大化する支援を行っています。「Retrieval」というテクノロジーと、狩猟犬や盲導犬としてのレトリバー犬に由来する社名には、必要な情報を迅速に提供し、パートナーとして信頼される存在でありたいという思いが込められています。これからもAIによるデジタル変革を促進し、企業活動の進化に貢献していくことでしょう。
会社情報
- 会社名
- 株式会社レトリバ
- 住所
- 東京都新宿区西新宿2-1-1新宿三井ビル32F
- 電話番号
トピックス(IT)








【記事の利用について】
タイトルと記事文章は、記事のあるページにリンクを張っていただければ、無料で利用できます。
※画像は、利用できませんのでご注意ください。
【リンクついて】
リンクフリーです。