




日本語LLM発展の新たな一歩、Anoteとチャネルブリッジの提携
米国ニューヨークを拠点とするAnote, Inc.が、日本のAI業界に新しい風を吹き込む取り組みを発表しました。このプロジェクトは、「日本語大規模言語モデル(LLM)評価とファインチューニング」と銘打たれ、株式会社チャネルブリッジとの連携により実施されます。
本日より、プロジェクトの一環として、日本国内のAI開発企業や研究機関を対象にしたパイロットプログラムの参加者が募集されます。このプログラムは、Anoteが新たにリリースしたエンドツーエンドのMLOpsプラットフォームを中心に展開されます。プラットフォームの目指すところは、人間中心型のAI開発環境を整えることです。
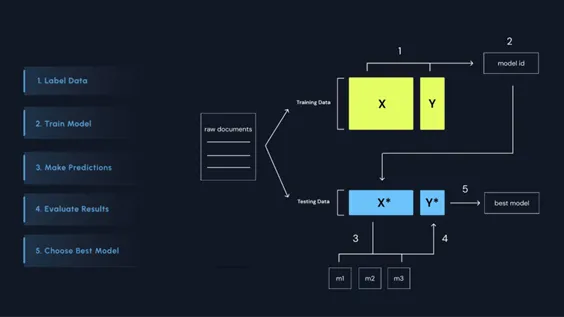
この取り組みは、データアノテーションからファインチューニング、推論、評価、そして統合に至るまで、日本語LLMを導入するための全プロセスを網羅するものです。Anoteは、さまざまなユーザーが自身のデータに最も適したLLMを構築できる環境を提供します。評価フレームワークでは、GPT、Claude、Llama3、Mistralなど、さまざまなLLMを比較することが可能です。さらに、専門知識をトレーニングプロセスに反映させることで、モデルの精度も向上させることができます。
本プロジェクトの背景には、日本語LLMが抱える深刻な課題があります。現時点で、LLMの学習データにおいて英語は60〜70%を占めていますが、日本語はわずか3〜5%です。このような状態が、日本語のAI利用において性能低下を引き起こしています。このプロジェクトによって、Anoteは日本語開発者や研究者に対する新しいツールとインフラを提供し、日本語AIの進化を目指しています。
主な対応する課題には以下のものが挙げられます:
Anoteのプラットフォームは、エンドツーエンドのMLOpsを可能にし、アノテーション、ファインチューニング、推論、評価、統合を一貫してサポートします。さらに、マルチモデルによる比較が可能で、GPT-4o、Claude 3.5、Llama 3、Mistralなどとファインチューニング済みモデルを日本語データで比較できます。
また、高度な評価フレームワークを通じて、Cosine SimilarityやRouge-L、LLM Evalといった多面的な評価が可能です。多様なタスクにも対応しており、テキスト分類や固有表現抽出(NER)、プロンプトQAもサポートしています。
現在、Anoteでは、ファインチューニングチャットボットの構築も可能であり、自社のドキュメントをアップロードし、質問を実施できる環境が整っています。このプロジェクトに参加することで、日本語を最適化したモデルの構築や、LLMを利用したプロダクト開発が実現できます。
プロジェクトに参加するための詳細は以下の通りです:
参加希望者は、Anote, Inc.(担当:Natan Vidra)までメールにてお問合せください。さらに、Anoteの日本国内パートナーである株式会社チャネルブリッジもサポートしています。これを機に、日本語のAI技術が飛躍的に進化することを期待しましょう。
公式ウェブサイトは Anote 及び チャネルブリッジ でご確認ください。

本日より、プロジェクトの一環として、日本国内のAI開発企業や研究機関を対象にしたパイロットプログラムの参加者が募集されます。このプログラムは、Anoteが新たにリリースしたエンドツーエンドのMLOpsプラットフォームを中心に展開されます。プラットフォームの目指すところは、人間中心型のAI開発環境を整えることです。
この取り組みは、データアノテーションからファインチューニング、推論、評価、そして統合に至るまで、日本語LLMを導入するための全プロセスを網羅するものです。Anoteは、さまざまなユーザーが自身のデータに最も適したLLMを構築できる環境を提供します。評価フレームワークでは、GPT、Claude、Llama3、Mistralなど、さまざまなLLMを比較することが可能です。さらに、専門知識をトレーニングプロセスに反映させることで、モデルの精度も向上させることができます。
日本語LLMの課題への挑戦
本プロジェクトの背景には、日本語LLMが抱える深刻な課題があります。現時点で、LLMの学習データにおいて英語は60〜70%を占めていますが、日本語はわずか3〜5%です。このような状態が、日本語のAI利用において性能低下を引き起こしています。このプロジェクトによって、Anoteは日本語開発者や研究者に対する新しいツールとインフラを提供し、日本語AIの進化を目指しています。
主な対応する課題には以下のものが挙げられます:
- - 日本語のトレーニングデータの不足と質の問題:高品質かつ大規模な日本語トレーニングデータセットの生成を支援します。
- - 日本語LLM評価基準の欠如:日本初の公開型LLM評価データセットや指標を設け、業界全体の基準を確立します。
- - ファインチューニング環境へのアクセス制限:Anoteのプラットフォームを駆使して、ユーザーは自社データに基づいたカスタムLLMを構築し運用することが可能です。
Anoteのユニークな機能
Anoteのプラットフォームは、エンドツーエンドのMLOpsを可能にし、アノテーション、ファインチューニング、推論、評価、統合を一貫してサポートします。さらに、マルチモデルによる比較が可能で、GPT-4o、Claude 3.5、Llama 3、Mistralなどとファインチューニング済みモデルを日本語データで比較できます。
また、高度な評価フレームワークを通じて、Cosine SimilarityやRouge-L、LLM Evalといった多面的な評価が可能です。多様なタスクにも対応しており、テキスト分類や固有表現抽出(NER)、プロンプトQAもサポートしています。
現在、Anoteでは、ファインチューニングチャットボットの構築も可能であり、自社のドキュメントをアップロードし、質問を実施できる環境が整っています。このプロジェクトに参加することで、日本語を最適化したモデルの構築や、LLMを利用したプロダクト開発が実現できます。
募集概要
プロジェクトに参加するための詳細は以下の通りです:
- - 対象:日本国内で生成AIもしくはLLM開発に関わる企業や研究機関。
- - 募集数:最大5組織。
- - プロジェクト期間:2025年6月1日〜10月1日。
- - 応募締切:2025年5月17日。
参加希望者は、Anote, Inc.(担当:Natan Vidra)までメールにてお問合せください。さらに、Anoteの日本国内パートナーである株式会社チャネルブリッジもサポートしています。これを機に、日本語のAI技術が飛躍的に進化することを期待しましょう。
お問い合わせ
- - Anote, Inc.: Email: [email protected]
- - 株式会社チャネルブリッジ: Email: [email protected]
公式ウェブサイトは Anote 及び チャネルブリッジ でご確認ください。
会社情報
- 会社名
- 株式会社チャネルブリッジ
- 住所
- 東京都港区赤坂8丁目4-14青山タワープレイス8F
- 電話番号
- 03-6824-6520
トピックス(IT)








【記事の利用について】
タイトルと記事文章は、記事のあるページにリンクを張っていただければ、無料で利用できます。
※画像は、利用できませんのでご注意ください。
【リンクついて】
リンクフリーです。