




音声認識の新時代を切り開く日本語話者分離モデル「Sepamato」
日本語音声を変える!新時代の話者分離モデル「Sepamato」
甘党AI株式会社が司法に革新をもたらす日本語音声の話者分離モデル「Sepamato」を開発しました。このモデルは、複雑な環境下でも高精度に音声を分離することが特徴です。特に、日本語に最適化されているため、これまでの技術では困難だった状況でも、より正確な音声認識を実現します。
開発の背景:音声認識AIの進化と課題
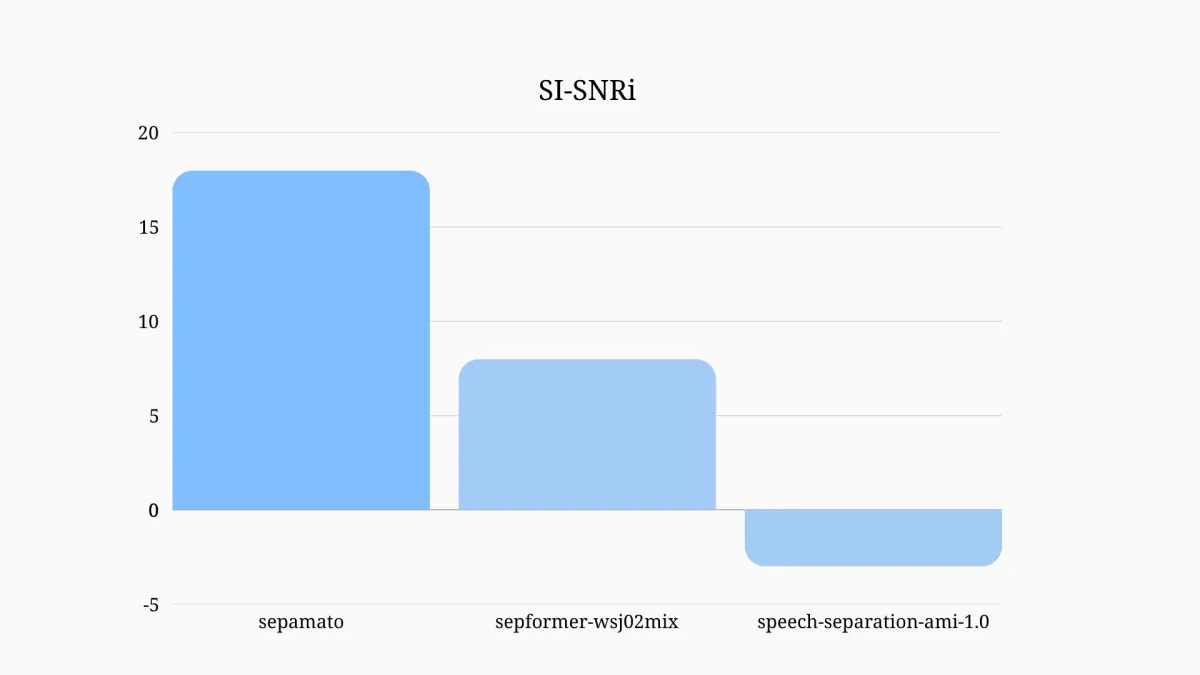
音声認識技術は日々進化していますが、会議やライブ配信、接客などの現場では、環境音や複数の話者が同時に発話することで、音声認識モデルの性能が制限されることが課題です。特に日本語に最適化されたモデルが少なく、既存の公開話者分離モデルは主に英語を中心に学習されているという現実もあります。そこで「Sepamato」は、日本語音声データを用いて学習を行い、従来のモデルに対してSI-SNRi評価で2倍以上の改善を達成しました。
Sepamatoの機能と利用シーン
「Sepamato」は特に以下のようなシーンで威力を発揮します。
- - 放送のポストプロダクション: 動画やポッドキャスト制作時に、高精度で字幕を生成。話者ごとの音声を分離することで、音声翻訳や多言語吹き替えが効率化されます。
- - 接客業のサービス向上: 従業員の声と顧客の声を分けることで、対応状況をより正確に評価し、個別のフィードバックを提供します。
- - 音声認識システムへの組み込み: オンプレミス環境への統合が可能で、議事録アプリや音声関連アプリの前処理として機能し、書き起こし精度を向上させます。
- - データセット作成: 機械学習モデル開発に必要な大量の音声データを容易に構築できます。
「Sepamato」の将来性
「Sepamato」は、甘党AIの会話分析サービス「Rokavox」を通じて提供される予定で、さまざまな場面での応用が期待されています。また、特定の話者や特定の語彙に対する追加学習も可能で、ユーザーのニーズに応じた最適化が進められる環境が整えられています。
日本語音声に特化した「Sepamato」の開発は、音声認識AIの新しい可能性を切り開くものとなります。今後の商業利用や実際のプロジェクトへの適用も期待されています。お問い合わせを希望される方は、甘党AIのサイトを通じてご相談ください。

会社情報
- 会社名
- 甘党AI株式会社
- 住所
- 福島県会津若松市一箕町鶴賀字下居合145番地2
- 電話番号
トピックス(IT)








【記事の利用について】
タイトルと記事文章は、記事のあるページにリンクを張っていただければ、無料で利用できます。
※画像は、利用できませんのでご注意ください。
【リンクついて】
リンクフリーです。