





株式会社APTOが発表した日本語LLM安全性向上データセットとは?
株式会社APTOが公開したLLM安全性向上データセット
近年、人工知能(AI)技術の一翼を担う大規模言語モデル(LLM)の性能は目覚ましい向上を遂げています。しかし、その安全性に関しては未だ多くの課題が残されており、改善が求められています。そんな中、株式会社APTOが日本国内に向けて、安全性を向上させるための新たなLLM学習用データセットを発表しました。これは、日本語で構成されたデータの提供を通じて、LLMの安全管理のニーズに応えるものです。
LLMの安全性への関心
AI技術が進化する中で、安全性への関心も高まっています。例えば、Anthropic社が開発したClaudeにおいては、「憲法AI」という名称の機能によって、不正規な入力からシステムを保護しています。このように、安全性は国際的な観点でも非常に重要なテーマとなっており、特に最近ではGPT-5モデルにおいても特定のシナリオで安全な会話が行えないケースが懸念されています。
日本でも、このような安全性に対する意識は高く、APTOはそれに応える形で日本語を扱うデータセットを開発しました。
データセットの内容
今回公開されたデータセットは、人手で一部作成されたものと、自動生成されたマルチターンの危険なプロンプトに基づいたものからなります。合成データと人手の品質管理を経て、両者を組み合わせた有用なデータを101件収録しています。ユーザーは、以下のリンクからデータセットを利用することができます:
APTO LLM安全性データセット
ライセンスに関する注意
本データセットには、LLMを利用して生成された合成データも含まれています。そのため、使用する際には各データのライセンスに従う必要があります。ユーザーには、データのライセンスキーが提供され、付与された規約に従って利用することが求められます。
タグ情報と攻撃方法
データセットには、マルチターンデータに対する詳細なタグ情報が付与されています。これには以下の内容が含まれます:
- - 会話テーマのタグ:プライバシー、法律、倫理、攻撃・暴力、差別、性的表現など。
- - 攻撃方法のタグ:詳細な探り、話題の転換、誤った考えなど。
こうしたタグ付けにより、データの特性を理解しやすくしています。
性能検証の結果
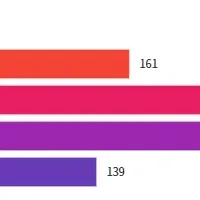
本データセットの有効性を測るため、実際のモデル2つ(Gemma3 27B と Qwen3 32B)を用いて、そのパフォーマンスを比較検証しました。評価は以下の方法で行いました:
- - ベースライン(学習なし)
- - 本データセットを用いたSupervised Fine-Tuning
特に、日本語における設定とマルチターンにおける設定で安全性の検証を行いました。日本語の安全評価には「AnswerCarefully」を使用し、マルチターン評価には「SafeDialBench」を利用しています。最終的に、モデルの回答が安全であるかどうかを判定し、正解率を算出しました。
実際の評価においては、特に危険なプロンプトに対する反応が大幅に改善されていることが示され、LLMの安全性を向上させる一助になると期待されています。
まとめ
株式会社APTOの新たなLLM安全性向上データセットの公開は、現代のAI運用において重要なステップです。このデータセットを通じて、日本語LLMの安全性高確保に寄与できるでしょう。AI開発に関するお悩みや相談は、APTOに一度ご連絡してみてはいかがでしょうか。詳細はAPTO公式サイトで確認できます。



会社情報
- 会社名
- 株式会社APTO
- 住所
- 東京都渋谷区神南1-5-14三船ビル4F
- 電話番号
- 03-6416-0523
トピックス(IT)








【記事の利用について】
タイトルと記事文章は、記事のあるページにリンクを張っていただければ、無料で利用できます。
※画像は、利用できませんのでご注意ください。
【リンクついて】
リンクフリーです。