



AIが重要な知識を意図的に忘却できる新技術の開発
新技術「近似ドメインアンラーニング」の創出
1. 技術の概要
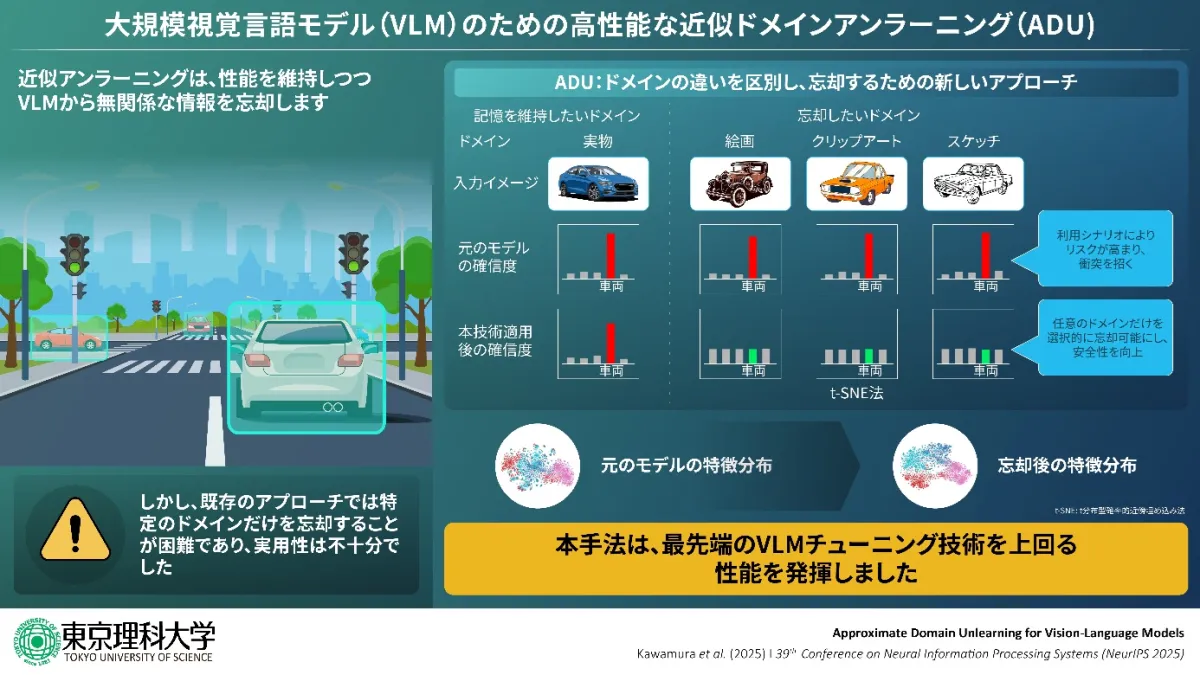
東京理科大学の研究チームが発表した技術、近似ドメインアンラーニング(Approximate Domain Unlearning: ADU)は、事前学習済みの大規模視覚言語モデルに対し、特定のドメインに属する知識だけを選択的に忘却させることができる世界初の取り組みです。この技術は、AIが誤認を犯すリスクを低減し、用途に応じて知識を柔軟に制御する可能性を開きます。
2. 研究の背景
AIは、高精度で物体を認識できる能力を持つ一方で、場合によっては誤認識や信頼性の問題を引き起こすことがあります。例えば、交通監視システムや自動運転車は、実物ではない画像を実物と誤認識することにより、誤った解析結果を生成する可能性があります。これに対処するため、AIの持つ不要な知識を選択的に削除する技術が求められています。
3. 新技術の詳細
3.1 分離と特徴の捉え方
今回の技術では、まず、特徴空間上で異なるドメイン間の情報を清晰に分離するための『Domain Disentangling Loss (DDL)』を導入しました。これにより、例えば写真や絵画の画像を、異なるドメインとして効果的に分けることが可能になります。また、個々の画像において異なるドメインの特性を捉えるために『Instance-wise Prompt Generator (InstaPG)』という機構も設けられ、これにより画像ごとのドメインの違いに柔軟に対応します。
3.2 性能評価
この技術は、4種類の標準的な画像認識データセットを使用して評価され、従来手法に比べて平均約1.6倍の性能向上を達成することが確認されました。特に、過酷な条件下でも約1.7倍の改善を記録しており、その効果が実証されています。これにより、従来の技術に比べてより柔軟で信頼性の高いAIの実現が期待されます。
4. 今後の展望
本研究の成果は、2025年の国際会議『Neural Information Processing Systems (NeurIPS 2025)』でも発表される予定で、今後のAIの発展に多大な影響を与えることが期待されています。また、レジリエンスの高いAIシステムの構築、及びその効率的な再利用が進むことで、AI技術の適用範囲が拡大するでしょう。
4.1 研究者のコメント
入江豪准教授は、「この技術は、機能的なAIの運用を持続可能なものにするために、特定の目的に応じた知識の制御が不可欠であることを示しています。私たちの研究が、より安全で信頼性のあるAIモデルの実現に寄与することを願っています」と述べています。
5. お問い合わせ
本研究に関する詳細や問い合わせは、東京理科大学の入江豪准教授、または産業技術総合研究所にて受け付けています。この技術の開発が、AIの未来をどう変えるのか、引き続き注目が集まります。

会社情報
- 会社名
- 学校法人東京理科大学
- 住所
- 東京都新宿区神楽坂1-3
- 電話番号
- 03-3260-4271
トピックス(科学)


【記事の利用について】
タイトルと記事文章は、記事のあるページにリンクを張っていただければ、無料で利用できます。
※画像は、利用できませんのでご注意ください。
【リンクついて】
リンクフリーです。